|
I am a final year master's student in the Computer Science and Technology College at Nanjing University of Aeronautics and Astronautics. During my master's studies, my thesis focuses on using vision-language representation learning and multimodal foundation models (e.g., multimodal LLMs) for modeling human visual attention (eye gaze). Meanwhile, I have a strong interest in multiple research directions including Autonomous Driving, AIGC, and VLMs (Vision-Language Models). I am fortunate to be advised by Rong Quan (dissertation advisor), Dong Liang, Wentong Li, and Jie Qin. Previously, I was an undergraduate student at the School of Internet at Anhui University, majoring in Intelligent Science and Technology, where I primarily studied foundational theories related to computer science and artificial intelligence. |

|
|
|
I am broadly interested in Computer Vision, Autonomous Driving and Multimodal AI (AIGC, Vision-Language models). During my master's studies, my research primarily focuses on leveraging vision-language representation learning and multimodal foundation models (e.g., multimodal LLMs) for modeling human visual attention (eye gaze). For more details, refer to my résumé. |

|
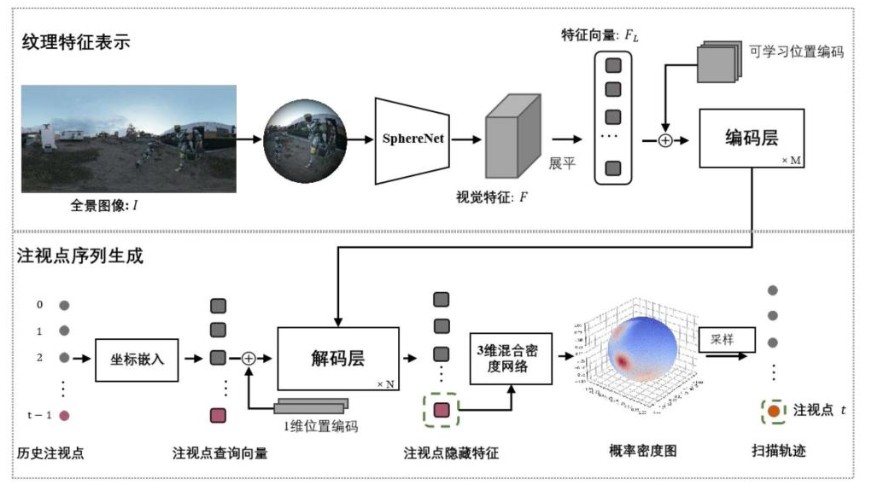
Rong Quan*, Yantao Lai*, Mengyu Qiu, Dong Liang† ECCV, 2024 PDF / Bibtex / Code |
|
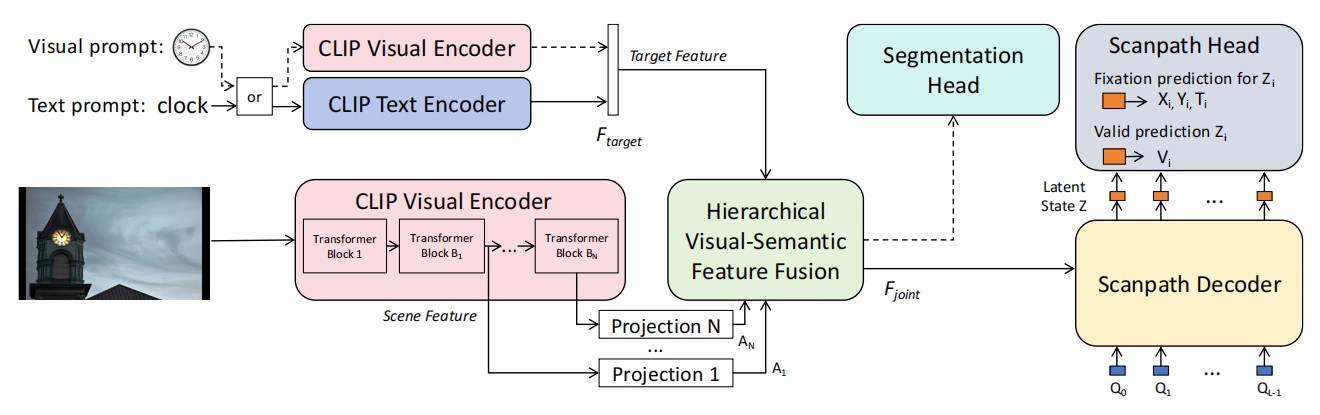
Rong Quan, Yantao Lai, Dong Liang, Mengyu Qiu, Jie Qin, Patent, Granted PDF / Bibtex / Code |
|
Yantao Lai, Rong Quan, Dong Liang†, Jie Qin, ICASSP oral, 2025 PDF / Bibtex / Code |

|
Rong Quan, Yantao Lai, Dong Liang, Jie Qin, Patent, Disclosed PDF / Bibtex / Code |
|
|